
A Dictionary Learning-based 3D Morphable Shape Model
Published in IEEE Transactions on Multimedia (TMM), 2017
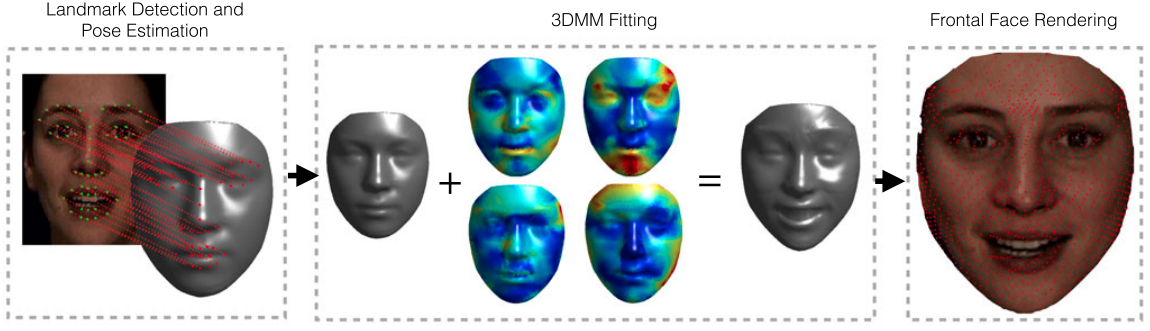
In this paper, we propose a new approach for constructing a 3D morphable shape model (called DL-3DMM) and show our solution can reach the accuracy of deformation required in applications where fine details of the face are concerned. For constructing the model, we start from a set of 3D face scans with large variability in terms of ethnicity and expressions. Across these training scans, we compute a point-topoint dense alignment, which is accurate also in the presence of topological variations of the face. The DL-3DMM is constructed by learning a dictionary of basis components on the aligned scans. The model is then fitted to 2D target faces using an efficient regularized ridge-regression guided by 2D/3D facial landmark correspondences in order to generate pose-normalized face images. Comparison between the DL-3DMM and the standard PCA-based 3DMM demonstrates that in general a lower reconstruction error can be obtained with our solution. Application to action unit detection and emotion recognition from 2D images and videos shows competitive results with state of the art methods on two benchmark datasets. Download paper here
If you find our work useful, please cite us:
@article{ferrari2017dictionary,
title={A dictionary learning-based 3D morphable shape model},
author={Ferrari, Claudio and Lisanti, Giuseppe and Berretti, Stefano and Del Bimbo, Alberto},
journal={IEEE Transactions on Multimedia},
volume={19},
number={12},
pages={2666–2679},
year={2017},
publisher={IEEE}}